【デモあり】ELYZA、商用利用可能な130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」を一般公開
既存のオープンな日本語モデルの中で最高性能、175BのGPT-3.5 (text-davinci-003) を上回る性能を達成

本モデルは、パラメータ数が130億に増加したことに加え、事後学習に使用するデータを更に増強したことで、「ELYZA-japanese-Llama-2-7b」を上回る性能を実現しています。また、ELYZAが公開している日本語ベンチマークであるELYZA Tasks 100を用いたブラインドテストでは、130億パラメータモデルにも関わらず、既存のオープンな700億パラメータモデルをも上回る結果となっています。
ライセンスはLlama 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
公開した各種モデルの詳細は、note記事に記載しております。
https://note.com/elyza/n/n5d42686b60b7
また、チャット形式のデモについてもHugging Face hub上で公開しています。デモを公開するにあたり、vLLMというライブラリを用いて推論の高速化を行ないました。高速化が体験に与える恩恵は我々の当初想定よりも大きく、その効果を最大限体感していただくため A100 GPU を使用したデモ提供を決めました。
以下のリンクからデモを触っていただくことができます。日本語性能や高速化の効果をぜひ体感してください。
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-13b-instruct-demo
※アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
なお一定期間後は、13B モデルを低コストで運用するための手段として検証中である、量子化したモデルとデモの公開を検討しています。
■ニュースサマリ
「Llama 2 13B」ベースの商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-13b」を一般公開
13Bながら70Bモデルを含むオープンな日本語モデルの中で最高性能、175BのGPT-3.5 (text-davinci-003) を上回る性能を達成
研究および商業目的での利用が可能
高速に動作するChat形式のデモも併せて公開
現在進行中のAI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI) の大規模言語モデル構築支援プログラムにて、700億パラメータモデルの開発も進行中
■今回のモデルについて
「ELYZA-japanese-Llama-2-13b」はMetaの「Llama-2-13b-chat」に対して、約180億トークンの日本語テキストで追加事前学習を行ったモデルです。学習に用いたのは、OSCARやWikipedia等に含まれる綺麗な日本語テキストデータです。複数のバリエーションがあり、ユーザーからの指示に従い様々なタスクを解くことを目的としてELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-13b-instruct」や、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-13b-fast」が存在します。
性能についてELYZA独自作成のデータセットを用いて評価した結果、「ELYZA-japanese-Llama-2-13b-instruct」については、13Bモデルながら70Bモデルを含むオープンな日本語LLMの中で最高のスコアを獲得しました。また「Qwen-14B」を除く日本語LLMの中では唯一、クローズドなモデルであり 1750億(175B)パラメータの GPT-3.5(text-davinci-003)を上回る結果となっています。
また「ELYZA-japanese-Llama-2-13b-fast」では、前回の「ELYZA-japanese-Llama-2-7b-fast」で作成したトークナイザーを更に効率化するためにいくつかの改良を加えることで、前回(13,042個)よりも少ない12,581個の日本語の語彙追加で、同じ日本語の文章を表すのに必要なトークン数を元の「Llama 2」の47%まで削減することに成功しています(前回は55%)。推論速度に換算すると、約2.27倍の性能を実現しました。
図1 70Bモデルを含むオープンな日本語モデルの中で最高性能
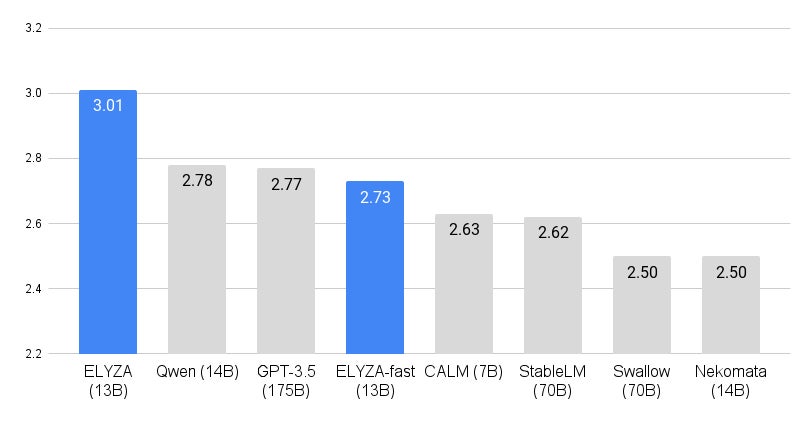
図2 1750億パラメータを有するGPT-3.5 (text-davinci-003)を上回る性能
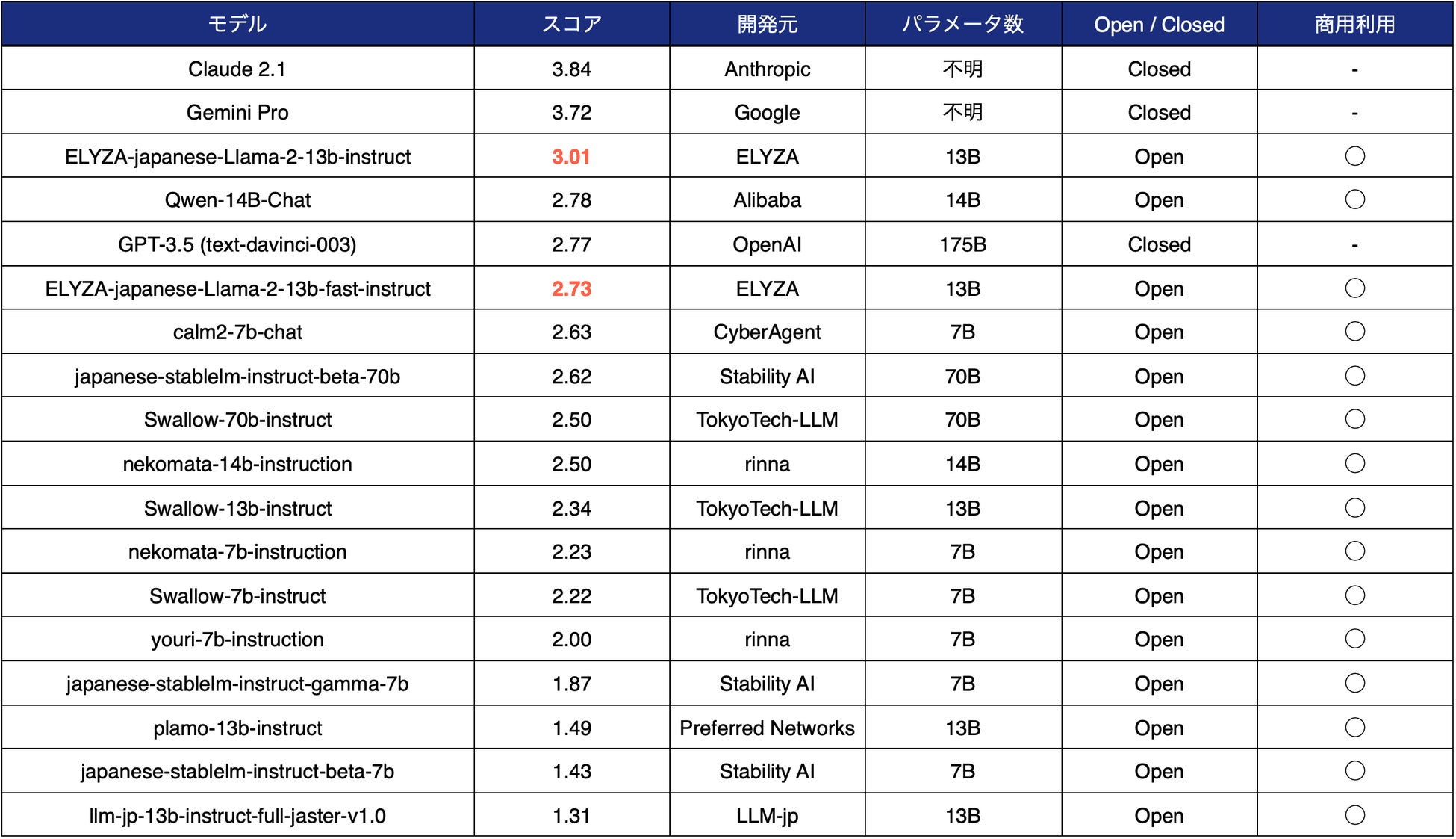
※ELYZA独自作成の「ELYZA Tasks 100」による性能評価。データセットの詳細と具体的な結果についても技術ブログにて公開。
図3-1 実際の出力例①(「ELYZA-japanese-Llama-2-13b-instruct」による)

図3-2 実際の出力例②(「ELYZA-japanese-Llama-2-13b-instruct」による)
図3-3 実際の出力例③(「ELYZA-japanese-Llama-2-13b-instruct」による)

その他、note記事にて以下内容を詳しく扱っています。ぜひご覧ください。
https://note.com/elyza/n/n5d42686b60b7
・公開モデルの全バリエーション詳細
・性能評価結果の詳細(ELYZA Tasks 100)
・ELYZA 7Bモデルとの出力結果比較
また、本モデルを用いたchatUI形式のデモも公開しております。日本語性能や高速化の効果をぜひ体感してください。
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-13b-instruct-demo
※アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
■付記および今後の展望
今回のモデル学習は、AI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI)を利用して実施しました。引き続き70Bモデルの開発も進行中です。さらに「Llama 2」での取り組みに限らず、海外のオープンなモデルの日本語化や、独自のLLMの開発に継続して投資をしてまいります。
■ELYZA会社概要
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形で言語生成AIの導入実装を推進します。
<会社概要>

社名 :株式会社ELYZA
所在地 :〒113-0033 東京都文京区本郷3-15-9 SWTビル 6F
代表者 :代表取締役 曽根岡侑也
設立 :2018年9月
URL :https://elyza.ai/
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像